QMD - 本地文档智能搜索引擎
产品定位
QMD(Query Markup Documents)是一款运行在本地设备上的智能文档搜索引擎,专为个人笔记、会议记录、文档和知识库的检索场景设计。
它的核心特征可以概括为三个维度:
- 本地运行,保护隐私:所有数据和处理均在本地完成,基于 GGUF 模型通过 node-llama-cpp 运行,无需联网,无需担心数据泄露
- 关键词 + 自然语言双模搜索:融合 BM25 全文检索、向量语义检索与 LLM 重排序能力,既支持精准的关键词匹配,也理解自然语言的语义表述
- AI Native,专为 Agent 设计:提供 MCP 协议集成、结构化 JSON 输出、HTTP 传输模式等多种适配 AI Agent 工作流的接口
无论你是管理个人知识库的开发者,还是需要快速检索大量文档的知识工作者,QMD 都能让你的本地文档真正成为可搜索、可理解的知识资产。

核心能力
QMD 提供三种检索模式,适配不同的速度与效果需求:
BM25 全文检索
速度最快的检索模式,基于 SQLite FTS5 构建倒排索引,适合关键词精准匹配场景。
qmd search "project timeline"
qmd search "lsof"当你明确知道要搜索的关键词时,BM25 检索能在毫秒级返回结果。
向量语义检索
基于文档嵌入向量的相似度匹配,能理解同义表述和模糊意图,适合自然语言查询场景。
qmd vsearch "how to deploy"
qmd vsearch "whait is lsof" # 即使拼写错误,也能找到相关内容向量检索会将文档分块后转化为语义向量,通过余弦相似度计算匹配程度,即使查询与文档没有共同关键词,只要语义相近就能命中。
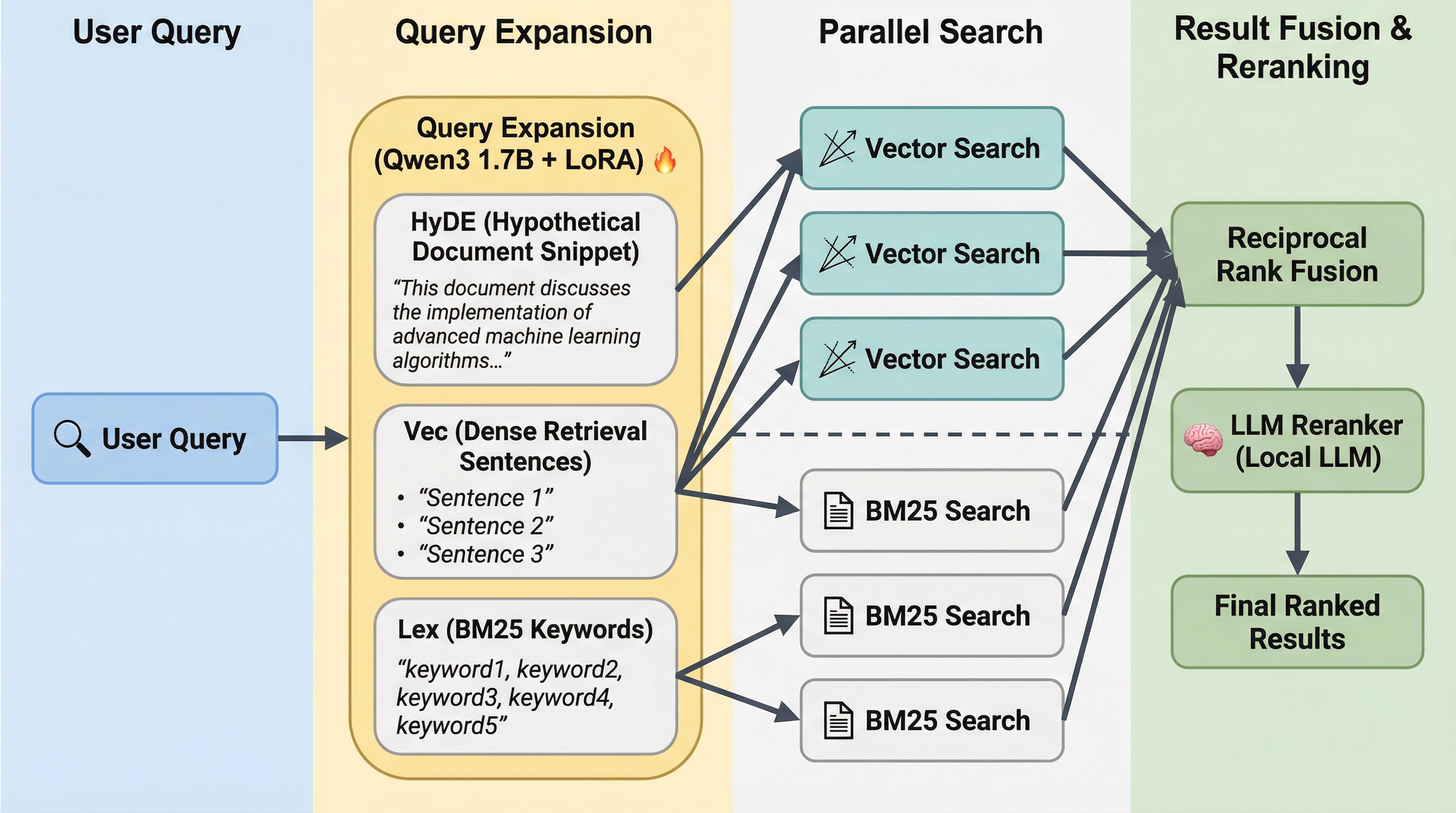
混合检索(推荐)
融合全文检索 + 向量检索 + LLM 查询扩展 + 重排序的多阶段流水线,检索质量最优,推荐日常使用。
qmd query "quarterly planning process"
qmd query "what is lsof"混合检索的工作流程:
- 查询扩展:通过微调的 LLM 生成查询变体,扩大召回范围
- 并行检索:同时执行 BM25 和向量检索,生成多个排序列表
- RRF 融合:使用倒数秩融合算法合并结果
- LLM 重排序:对候选结果进行交叉编码重排序,输出最终排序
三种模式的对比如下:
| 检索模式 | 命令 | 速度 | 适用场景 |
|---|---|---|---|
| BM25 全文检索 | qmd search | 最快 | 关键词精准匹配 |
| 向量语义检索 | qmd vsearch | 中等 | 自然语言、同义表述 |
| 混合检索 | qmd query | 较慢 | 日常使用,效果最优 |

完整工作流——从文档索引建立到文本搜索
QMD 的完整工作流由两条链路组成,通过共享的索引存储形成闭环:数据处理链路负责将本地文档转化为可搜索的索引,用户交互链路负责接收查询并返回检索结果。两条链路以索引存储为交汇点,数据写入与读取在此汇聚。
链路一:文档索引建立链路
这条链路将本地文档目录转化为可搜索的结构化索引,包含三个核心步骤:
1. 创建集合
将本地文档目录映射为可搜索的集合,支持 Glob 模式精确控制索引范围:
# 为个人笔记创建集合(默认索引所有 Markdown 文件)
qmd collection add ~/notes --name notes
# 指定 glob 模式,只索引特定文件类型
qmd collection add ~/docs --name docs --mask "**/*.{md,txt}"
# 索引代码文件
qmd collection add ~/code --name code --mask "**/*.{ts,js,py,go,rs}"集合是 QMD 的核心管理单元,每个集合对应一个本地目录。你可以按用途创建不同集合——个人笔记、工作文档、代码仓库——彼此隔离、独立管理。
2. 添加上下文
为集合附加描述性元数据,这些描述会随搜索结果一同返回,帮助 AI Agent 更好地理解文档背景,同时提升搜索相关性:
# 为集合添加上下文描述
qmd context add qmd://notes "Personal notes and ideas"
# 为集合内的子路径添加上下文
qmd context add qmd://docs/api "API documentation"
# 添加全局上下文,对所有集合生效
qmd context add / "Knowledge base for my projects"3. 生成嵌入向量
文档经智能分块后转化为语义向量,写入索引存储。Markdown 按语义结构(标题层级、代码块边界)分割,代码文件按函数和类边界分割:
# 为所有新增/修改的文档生成嵌入
qmd embed
# 强制重新生成所有文档的嵌入(更换模型后必须执行)
qmd embed -f
# 启用 AST 感知分块,针对代码文件优化
qmd embed --chunk-strategy auto处理完成后,数据写入中央索引存储,包含 BM25 倒排索引和向量索引。
链路二:用户交互链路
这条链路从索引存储读取数据,根据用户查询返回检索结果:
1. 用户输入查询
输入自然语言或关键词查询:
# 关键词查询
qmd search "API design"
# 自然语言查询
qmd vsearch "how to deploy application"
# 混合查询(推荐)
qmd query "quarterly planning process"2. 检索引擎处理
检索引擎从索引存储读取数据,根据查询选择检索模式。三种模式各有侧重:
- BM25 全文检索:速度最快,关键词精准匹配
- 向量语义检索:理解同义表述,模糊匹配
- 混合检索:全文 + 向量 + 查询扩展 + 重排序,效果最优
3. 返回搜索结果
最终返回包含以下信息的搜索结果:
- 文档标题
- 相关度分数(0-1 区间,0.8 以上为高度相关)
- 上下文描述(如果已配置)
- 匹配片段
# 混合检索,返回 10 条分数不低于 0.3 的结果
qmd query -n 10 --min-score 0.3 "API design patterns"
# 输出 JSON 格式,包含分数解释
qmd query --json --explain "quarterly reports"
# 在指定集合内检索
qmd search "API" -c notes流程图整体布局
┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────────┐
│ 创建集合 │───→│ 添加上下文│───→│ 生成嵌入 │────写入────→│ 索引存储 │
│ │ │ │ │ 向量 │ │ BM25+向量索引 │
└──────────┘ └──────────┘ └──────────┘ └──────┬───────┘
【数据处理链路】 │
│ 读取
↓
┌──────────┐ ┌──────────┐ ┌──────────────────────────────┐ ┌──────────┐
│ 用户查询 │───→│ 检索引擎 │───→│ 选择检索模式 │───→│ 返回结果 │
│ │ │ │ │ ┌──────┐ ┌──────┐ ┌──────┐ │ │ 标题+分数 │
└──────────┘ └──────────┘ │ │ BM25 │ │ 向量 │ │混合★│ │ │ 上下文 │
│ └──────┘ └──────┘ └──────┘ │ │ 匹配片段 │
【用户交互链路】 └──────────────────────────────┘ └──────────┘两条链路通过索引存储形成闭环:数据处理链路的终点是索引存储的写入端,用户交互链路的起点是索引存储的读取端。日常使用中,你只需在文档更新后执行 qmd update && qmd embed 刷新索引,之后便可随时检索。
获取文档内容和搜索演示
搜索找到相关文档后,你往往需要获取文档的具体内容。QMD 提供了精准的文档获取能力,支持从单文档到批量的多种获取方式。
单文档获取
通过文件路径或文档 ID(docid)获取指定文档内容,支持行范围控制:
# 通过文件路径获取
qmd get notes/meeting.md
# 通过搜索结果中的 docid 获取
qmd get "#abc123"
# 获取指定行范围(从第 50 行开始,最多 100 行)
qmd get docs/api.md:50 -l 100
# 指定起始行号与最大行数
qmd get docs/api-reference.md --from 50 -l 100注意:
qmd get直接从本地文件系统读取文件内容,而非从索引中获取。这确保了你获取的始终是最新内容,同时保持索引体积合理。
批量文档获取
通过通配符或逗号分隔列表批量获取文档:
# 通过通配符批量获取
qmd multi-get "journals/2025-05*.md"
# 通过逗号分隔的路径/docid 批量获取
qmd multi-get "doc1.md, doc2.md, #abc123"
# 限制仅获取 20KB 以内的文件
qmd multi-get "docs/*.md" --max-bytes 20480
# 输出 JSON 格式的批量结果
qmd multi-get "docs/*.md" --json搜索结果输出格式
检索结果支持多种输出格式,适配不同的使用场景:
# JSON 格式——供 AI Agent 或程序处理
qmd query "API design" --json -n 10
# 仅输出文件路径和分数——快速浏览相关文件
qmd query "error handling" --all --files --min-score 0.4
# Markdown 格式——适合文档集成
qmd search --md --full "error handling"
# CSV / XML 格式——适合数据导入
qmd query "quarterly reports" --csv
qmd query "quarterly reports" --xmlAI Agent 集成方式
QMD 专为 AI Agent 工作流设计,提供三种集成方式:
1. 命令行输出
直接使用命令行获取结构化 JSON 结果,供 LLM 解析处理:
qmd search "authentication" --json -n 10
qmd query "error handling" --all --files --min-score 0.42. MCP 服务集成
内置 Model Context Protocol 服务,与支持 MCP 的客户端深度集成,无需命令行调用:
{
"mcpServers": {
"qmd": {
"command": "qmd",
"args": ["mcp"]
}
}
}MCP 服务暴露四个核心工具:query(混合检索)、get(单文档获取)、multi_get(批量获取)、status(索引状态)。
Claude Code 用户可通过插件市场一键安装:
claude plugin marketplace add tobi/qmd
claude plugin install qmd@qmd3. HTTP 传输模式
启动 HTTP 服务,多个 Agent 共享使用,避免重复加载模型:
# 前台运行,默认端口 8181
qmd mcp --http
# 后台守护进程运行
qmd mcp --http --daemon
# 停止后台服务
qmd mcp stopHTTP 模式下,LLM 模型持续加载在显存中,嵌入与重排序上下文在空闲 5 分钟后释放,下次请求时透明重建,仅带来约 1 秒的额外耗时。任何 MCP 客户端均可通过 http://localhost:8181/mcp 连接该服务。
技术架构概述
Architecture
┌─────────────────────────────────────────────────────────────────────────────┐
│ QMD Hybrid Search Pipeline │
└─────────────────────────────────────────────────────────────────────────────┘
┌─────────────────┐
│ User Query │
└────────┬────────┘
│
┌──────────────┴──────────────┐
▼ ▼
┌────────────────┐ ┌────────────────┐
│ Query Expansion│ │ Original Query│
│ (fine-tuned) │ │ (×2 weight) │
└───────┬────────┘ └───────┬────────┘
│ │
│ 2 alternative queries │
└──────────────┬──────────────┘
│
┌───────────────────────┼───────────────────────┐
▼ ▼ ▼
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ Original Query │ │ Expanded Query 1│ │ Expanded Query 2│
└────────┬────────┘ └────────┬────────┘ └────────┬────────┘
│ │ │
┌───────┴───────┐ ┌───────┴───────┐ ┌───────┴───────┐
▼ ▼ ▼ ▼ ▼ ▼
┌───────┐ ┌───────┐ ┌───────┐ ┌───────┐ ┌───────┐ ┌───────┐
│ BM25 │ │Vector │ │ BM25 │ │Vector │ │ BM25 │ │Vector │
│(FTS5) │ │Search │ │(FTS5) │ │Search │ │(FTS5) │ │Search │
└───┬───┘ └───┬───┘ └───┬───┘ └───┬───┘ └───┬───┘ └───┬───┘
│ │ │ │ │ │
└───────┬───────┘ └──────┬──────┘ └──────┬──────┘
│ │ │
└────────────────────────┼───────────────────────┘
│
▼
┌───────────────────────┐
│ RRF Fusion + Bonus │
│ Original query: ×2 │
│ Top-rank bonus: +0.05│
│ Top 30 Kept │
└───────────┬───────────┘
│
▼
┌───────────────────────┐
│ LLM Re-ranking │
│ (qwen3-reranker) │
│ Yes/No + logprobs │
└───────────┬───────────┘
│
▼
┌───────────────────────┐
│ Position-Aware Blend │
│ Top 1-3: 75% RRF │
│ Top 4-10: 60% RRF │
│ Top 11+: 40% RRF │
└───────────────────────┘混合检索流水线
QMD 的核心混合检索采用多阶段流水线设计,兼顾检索精度与召回率:
查询输入 → 查询扩展 → 并行检索 → RRF 融合 → LLM 重排序 → 位置感知融合 → 结果输出各阶段的工作方式:
- 查询输入:接收用户的原始查询语句
- 查询扩展:通过微调的 LLM(qmd-query-expansion-1.7B)生成 2 个查询变体,同时保留原始查询并赋予 2 倍权重
- 并行检索:每个查询同时执行 BM25 全文检索与向量语义检索,生成多个排序列表
- RRF 融合:使用倒数秩融合算法(k=60)合并所有结果列表,原始查询结果赋予双倍权重,保留前 30 个候选结果
- LLM 重排序:通过 qwen3-reranker 模型对候选结果进行交叉编码重排序,输出 0-1 的相关性分数
- 位置感知融合:根据 RRF 排名调整检索分数与重排序分数的权重——排名靠前的结果保留更多检索分数,避免重排序破坏高置信度的精准匹配
- 结果输出:输出最终排序后的检索结果
智能分块策略
QMD 采用基于评分的智能分块算法,避免在语义单元中间截断,保证分块的语义完整性。
Markdown 分块
算法扫描文档中的所有自然断点,为不同断点赋予基础评分:
| 断点类型 | 评分 |
|---|---|
| H1 标题 | 100 |
| H2 标题 | 90 |
| H3 标题 | 80 |
| 代码块边界 | 80 |
| H4 标题 | 70 |
| 水平分隔线 | 60 |
| 段落空行 | 20 |
当接近 900 token 的分块目标时,算法在截止位置前 200 token 的窗口内,选择评分最高的断点进行分割,同时保护代码块不被截断。
AST 感知代码分块
对于代码文件,QMD 通过 tree-sitter 解析 AST 语法树,在语法边界进行分块:
| 语法结构 | 评分 |
|---|---|
| 类/接口/结构体定义 | 100 |
| 函数/方法定义 | 90 |
| 类型别名/枚举定义 | 80 |
| 导入/引用声明 | 60 |
支持 TS/JS、Python、Go、Rust 等语言,需通过 --chunk-strategy auto 启用。
分数归一化
QMD 对不同检索后端的原始分数进行统一归一化处理,映射至 0-1 区间:
| 检索方式 | 原始分数 | 归一化方法 |
|---|---|---|
| BM25 全文检索 | SQLite FTS5 输出值(0-25+) | 取绝对值处理 |
| 向量检索 | 余弦距离 | 1 / (1 + distance) |
| LLM 重排序 | 0-10 评分 | score / 10 |
分数相关性参考:
- 0.8 - 1.0:高度相关
- 0.5 - 0.8:中度相关
- 0.2 - 0.5:轻度相关
- 0.0 - 0.2:低相关性
本地模型依赖
QMD 首次使用时自动下载 3 个本地 GGUF 模型,缓存至 ~/.cache/qmd/models/:
| 模型 | 用途 | 大小 |
|---|---|---|
| embeddinggemma-300M-Q8_0 | 向量嵌入生成(默认) | ~300MB |
| qwen3-reranker-0.6b-q8_0 | 检索结果重排序 | ~640MB |
| qmd-query-expansion-1.7B-q4_k_m | 查询扩展(微调专属模型) | ~1.1GB |
所有模型均通过 node-llama-cpp 在本地运行,无需联网。对于中文等多语言场景,可将嵌入模型替换为 Qwen3-Embedding-0.6B(支持 119 种语言)。
使用技巧
Glob 模式精确匹配
使用 --mask 参数精确控制索引范围,只索引需要的文件类型,减少索引体积和处理时间:
# 只索引 Markdown 文件(默认行为)
qmd collection add ~/notes --name notes
# 同时索引 Markdown 和文本文件
qmd collection add ~/docs --name docs --mask "**/*.{md,txt}"分数阈值过滤
通过最小分数阈值过滤低相关性结果,提升结果质量:
# 只返回分数不低于 0.3 的结果
qmd query -n 10 --min-score 0.3 "API design patterns"
# 返回所有匹配结果,但过滤低相关性
qmd query "error handling" --all --min-score 0.4分数参考:0.8 以上为高度相关,0.5-0.8 为中度相关,0.2 以下通常可以忽略。
上下文提升搜索质量
为集合添加描述性上下文,能显著提升搜索相关性和 AI Agent 的理解能力:
# 为集合添加整体描述
qmd context add qmd://notes "Personal notes and ideas"
# 为子路径添加更细粒度的描述
qmd context add qmd://docs/api "API documentation"
# 查看已配置的上下文
qmd context list中文场景优化
默认嵌入模型(embeddinggemma)针对英语优化。对于中文、日语、韩语等多语言场景,建议替换为 Qwen3-Embedding 模型:
# 设置多语言嵌入模型
export QMD_EMBED_MODEL="hf:Qwen/Qwen3-Embedding-0.6B-GGUF/Qwen3-Embedding-0.6B-Q8_0.gguf"
# 更换模型后必须重新生成所有嵌入
qmd embed -f日常维护
# 查看索引状态、集合信息与上下文配置
qmd status
# 清理缓存与孤立数据,优化索引体积
qmd cleanup
# 重新索引所有集合并更新嵌入
qmd update && qmd embed